01
Chat & output
The core experience — and it is genuinely nice to use.
ACTIVITY TRACE
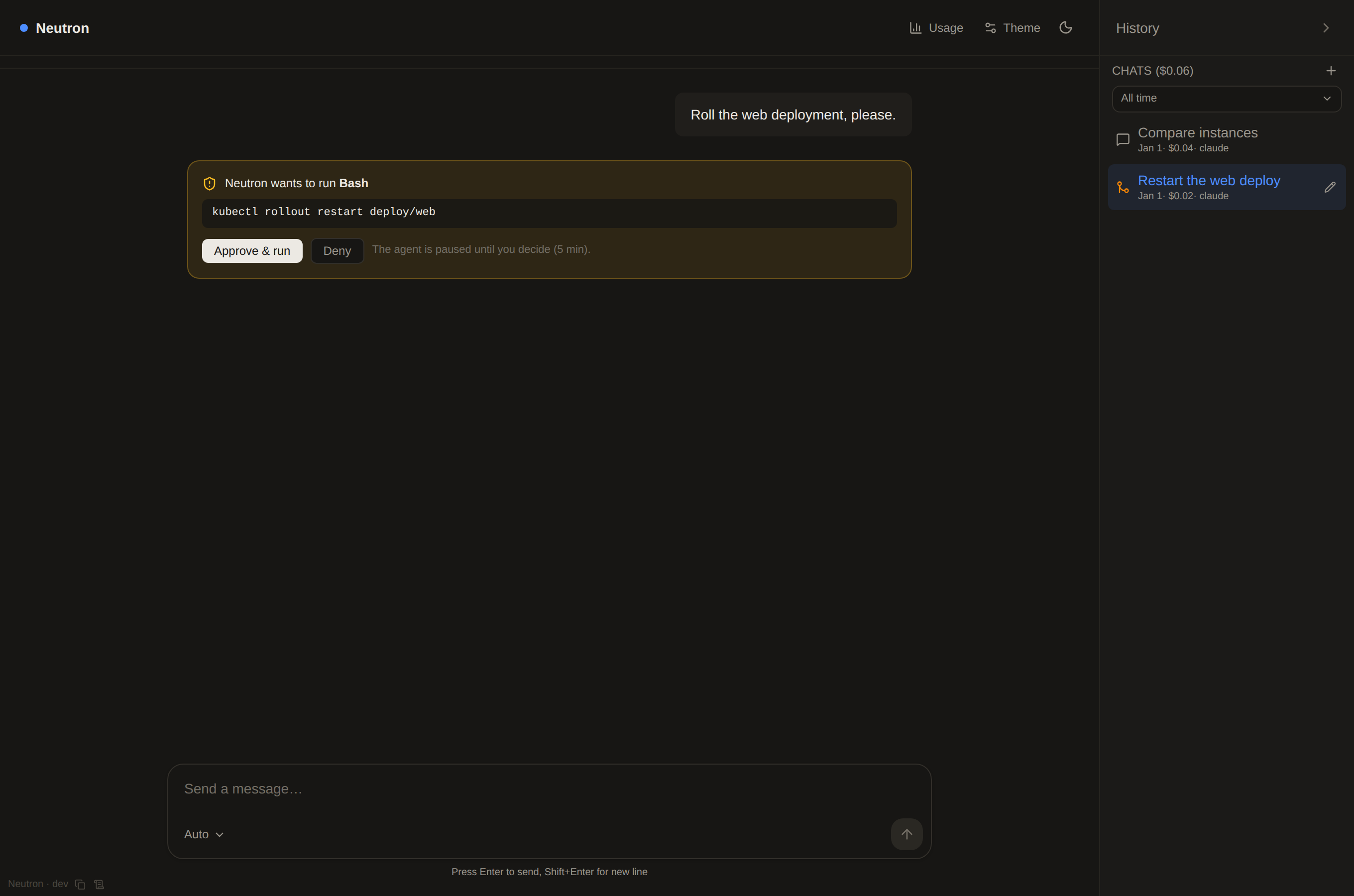
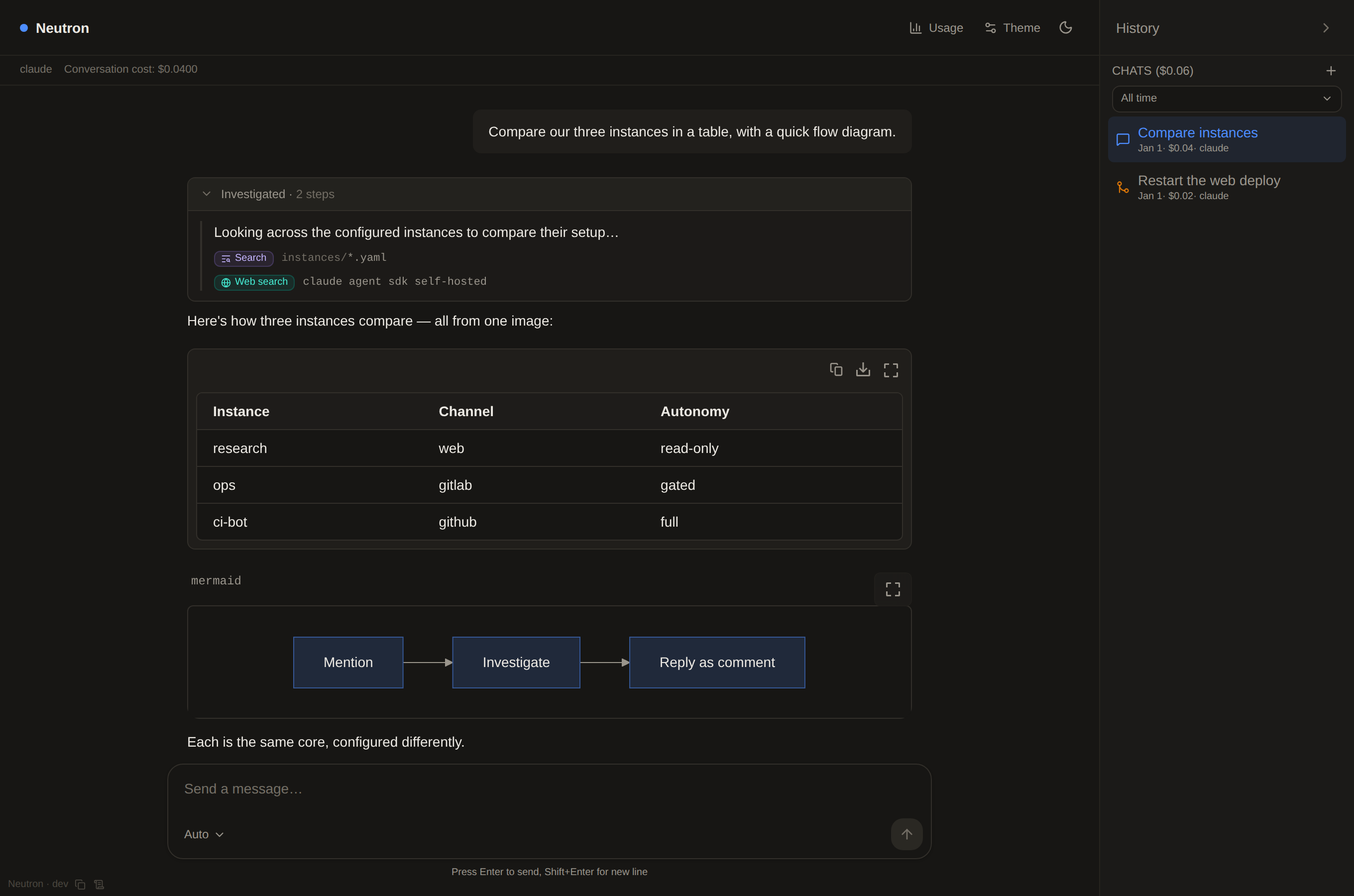
Watch it think
Answers stream token by token. Every tool call surfaces as a labelled chip; runs of read/search steps collapse into a single "gathered context" row so long investigations stay scannable.
- Live elapsed timer and status
- Colored, readable Mermaid and wrapping tables
- Per-turn cost + copy-answer
THEME
Themes, done properly
A semantic-token palette with dark, light, and system modes — applied before first paint, no white flash. Admins get a Theme dashboard: templates, code themes, and markdown accents.